
Photo by Transly Translation Agency on Unsplash
Datasets
The variable domain of heavy chain of heavy chain antibodies (VHHs), found in camelids such as alpacas and llamas, are promising therapeutic agents because of their small size, high stability, and high antigen-binding affinity.
By leveraging the simple structure of VHHs, which facilitates identification of full-length amino acid sequences by DNA sequencing technology, COGNANO has established a novel method for generating a digital library of VHH sequences and their binding activity to different antigens.
To facilitate the development of AI-driven antibody discovery, we released two labeled binding datasets, AVIDa-hIL6 and AVIDa-SARS-CoV-2, and the VHH sequence corpus.
AVIDa-hTNFa
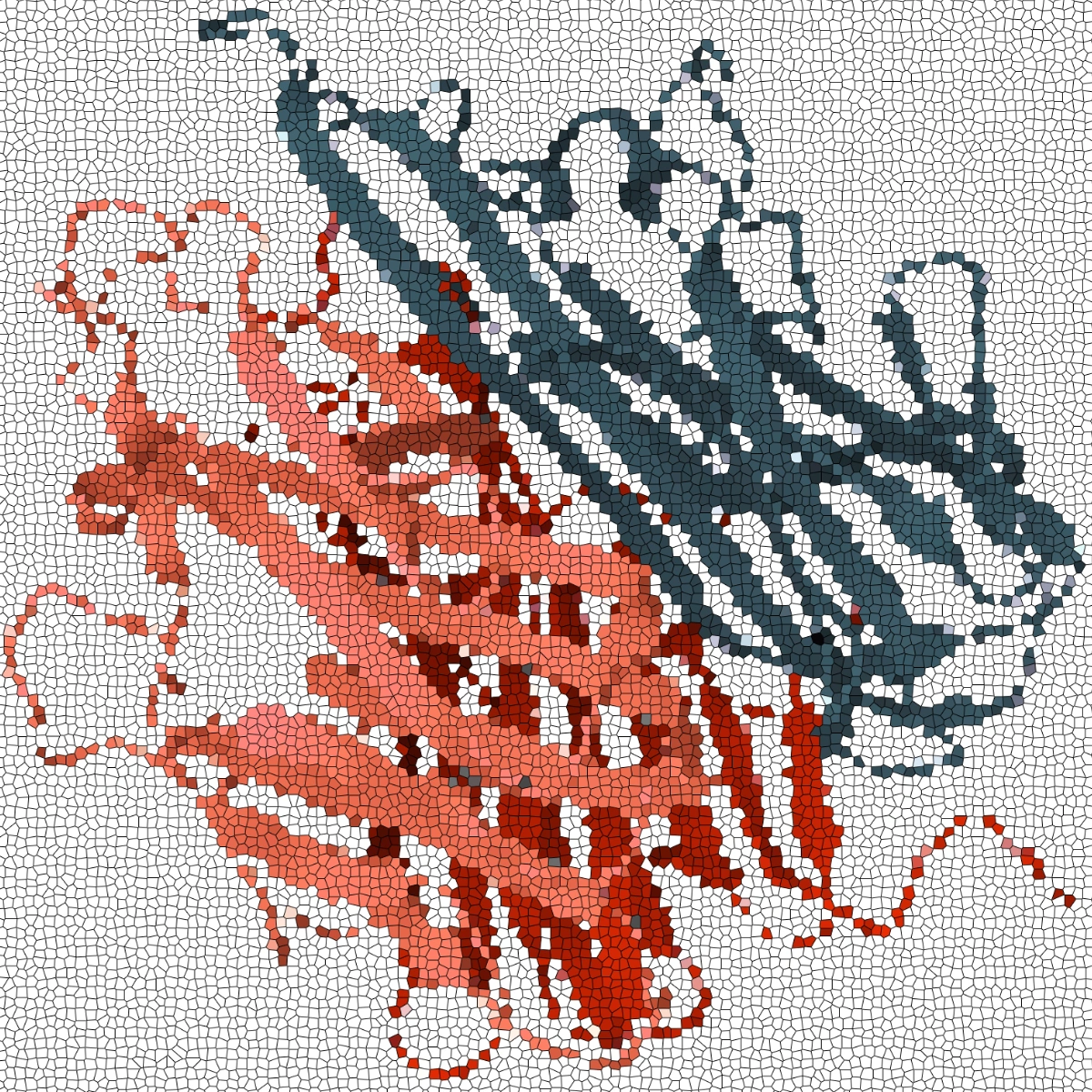
AVIDa-hTNFa is an antigen-antibody interaction dataset produced from two alpacas immunized with human tumor necrosis factor alpha (TNFa) protein. This dataset includes labels indicating whether the VHH sequences are binders or non-binders to the wild type TNFa protein.
AVIDa-hIL6
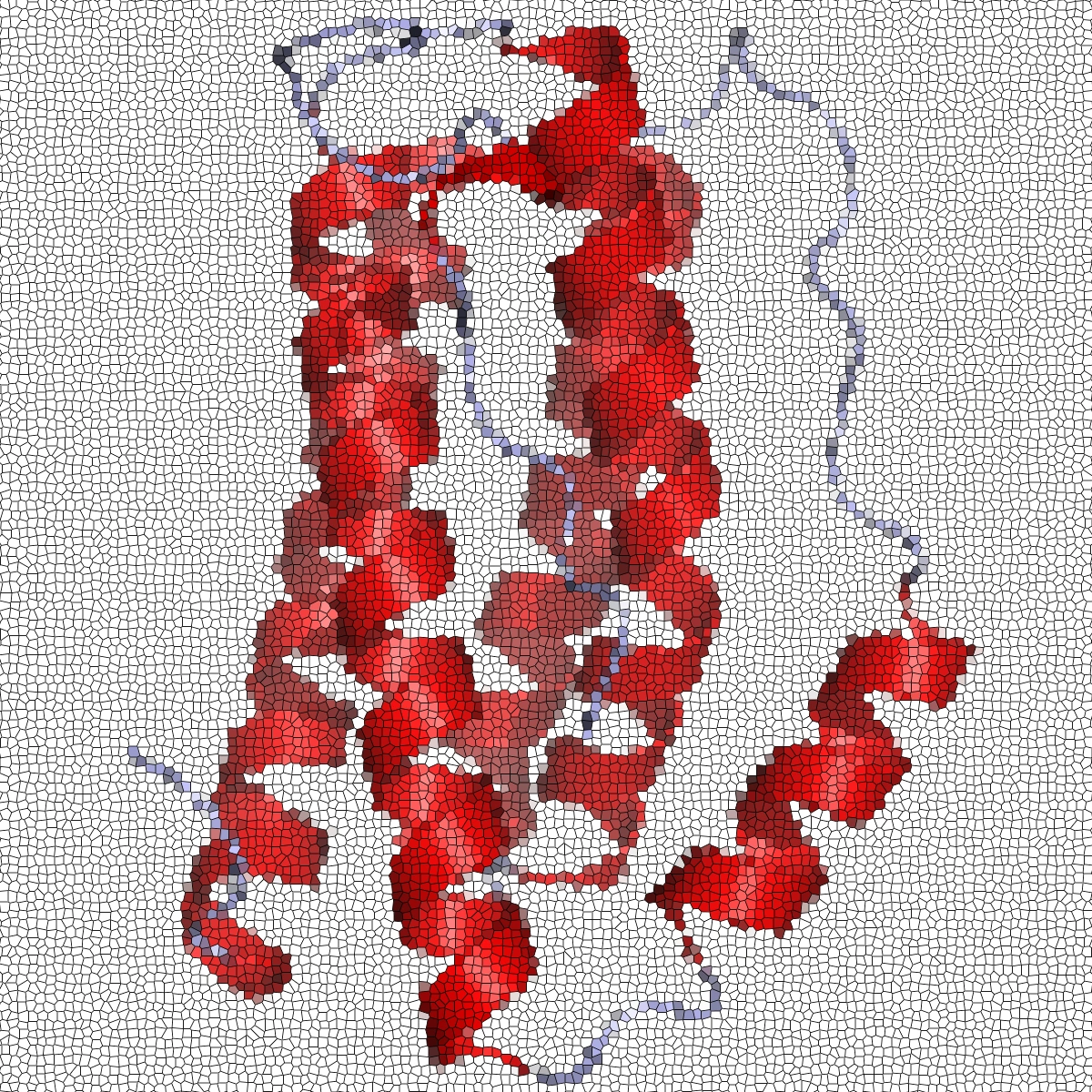
AVIDa-hIL6 is an antigen-variable domain of heavy chain of heavy chain antibody (VHH) interaction dataset produced from an alpaca immunized with the human interleukin-6 (IL-6) protein. By leveraging the simple structure of VHHs, which facilitates identification of full-length amino acid sequences by DNA sequencing technology, AVIDa-hIL6 contains 573,891 antigen-VHH pairs with amino acid sequences....
AVIDa-SARS-CoV-2
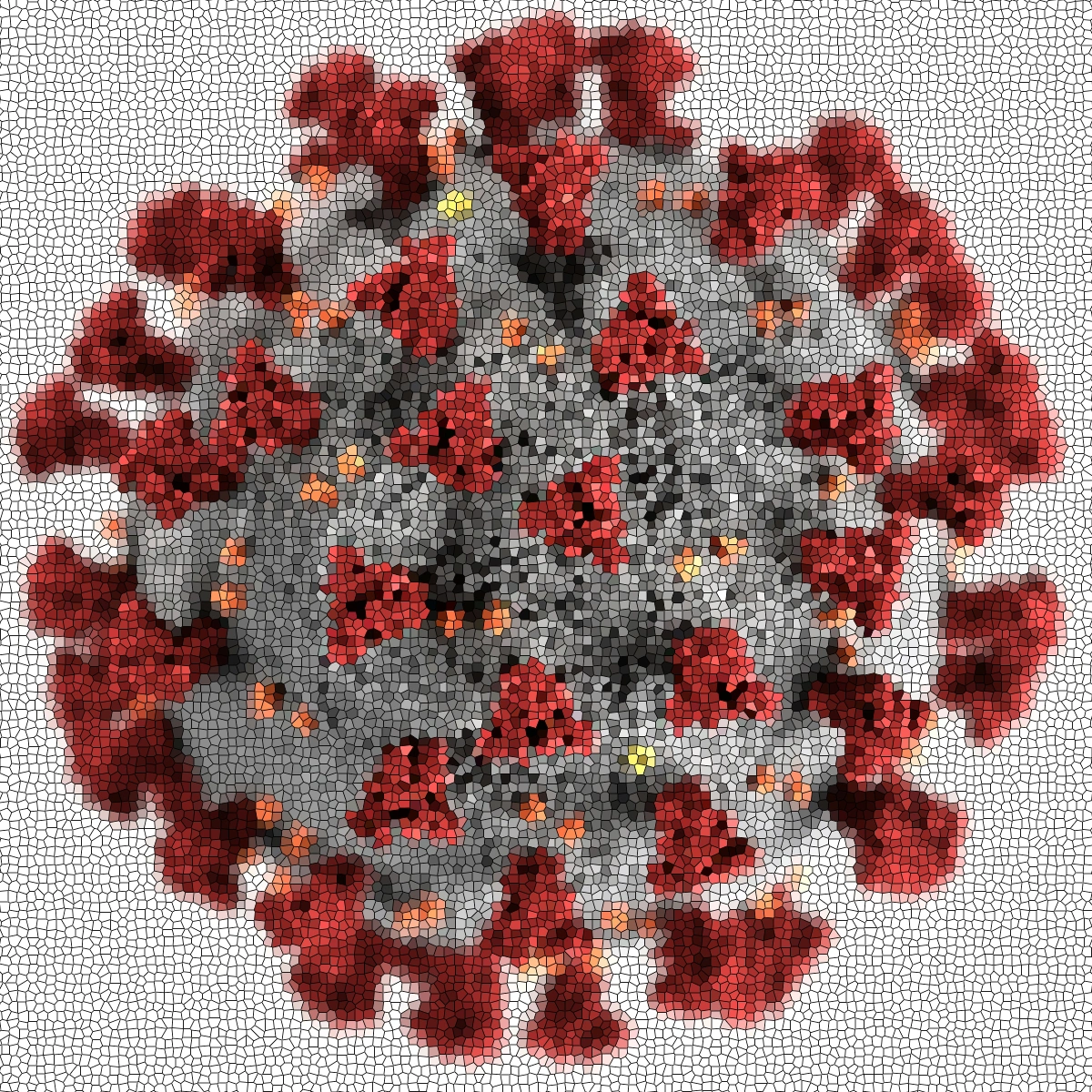
AVIDa-SARS-CoV-2 is a dataset featuring the antigen-variable domain of heavy chain of heavy chain antibody (VHH) interactions obtained from two alpacas immunized with severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) spike proteins. AVIDa-SARS-CoV-2 includes binary labels indicating the binding or non-binding of diverse VHH sequences to 12 SARS-CoV-2 mutants, such as the Delta and Omicr...

VHHCorpus
VHHCorpus is a pre-training corpus with full-length amino acid sequences of variable domain of heavy chain of heavy chain antibody (VHH) collected from alpacas. We currently released VHHCorpus-2M containing over two million unlabeled VHH sequences. VHHCorpus-2M can be used for pre-training of VHH-specific language models.