
Photo by Unsplash
VHHCorpus
VHHCorpus is a pre-training corpus with full-length amino acid sequences of variable domain of heavy chain of heavy chain antibody (VHH) collected from alpacas. We currently released VHHCorpus-2M containing over two million unlabeled VHH sequences. VHHCorpus-2M can be used for pre-training of VHH-specific language models.
Columns
A description of columns in the dataset CSV file.
Column | Description |
VHH_sequence | Amino acid sequence of VHH |
subject_species | Species of the subject from which VHH was collected |
subject_name | Name of the subject from which VHH was collected |
subject_sex | Sex of the subject from which VHH was collected |
Pipeline
VHHCorpus was generated through the following workflow. The scripts highlighted in blue are available on GitHub.
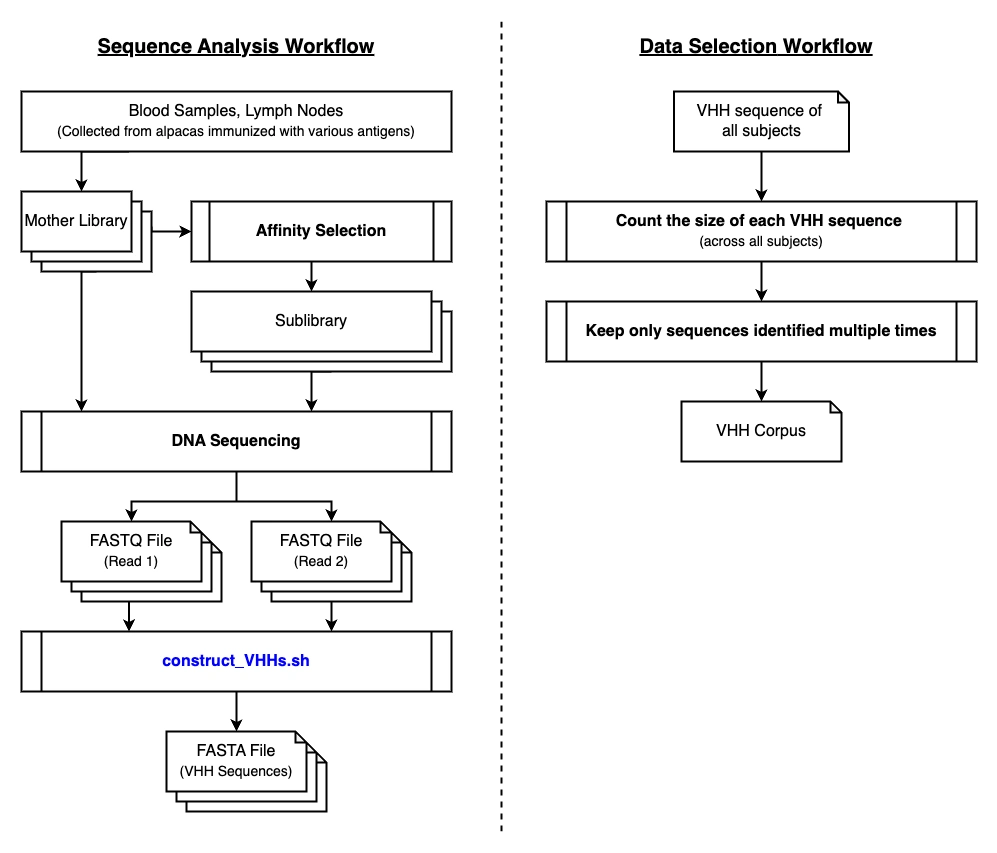
Subjects
VHHCorpus-2M is a collection of unique VHH sequences produced from five alpacas, different from those used in the generation of AVIDa-SARS-CoV-2. Note that VHHCorpus-2M includes publicly available AVIDa-hIL6 in addition to multiple datasets that have not been published as labeled binding datasets.
Name | Species | Sex |
Lucky | Alpaca | Female |
Marin | Alpaca | Male |
Wizzy | Alpaca | Male |
Yodel-Suri | Alpaca | Female |
Yuki | Alpaca | Female |
License
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.

If you want to use the dataset for commercial purposes, please contact [email protected].
Disclaimer
- Unless otherwise separately undertaken by the Licensor, to the extent possible, the Licensor offers the Licensed Material as-is and as-available, and makes no representations or warranties of any kind concerning the Licensed Material, whether express, implied, statutory, or other. This includes, without limitation, warranties of title, merchantability, fitness for a particular purpose, non-infringement, absence of latent or other defects, accuracy, or the presence or absence of errors, whether or not known or discoverable. Where disclaimers of warranties are not allowed in full or in part, this disclaimer may not apply to You.
- To the extent possible, in no event will the Licensor be liable to You on any legal theory (including, without limitation, negligence) or otherwise for any direct, special, indirect, incidental, consequential, punitive, exemplary, or other losses, costs, expenses, or damages arising out of this Public License or use of the Licensed Material, even if the Licensor has been advised of the possibility of such losses, costs, expenses, or damages. Where a limitation of liability is not allowed in full or in part, this limitation may not apply to You.
- The disclaimer of warranties and limitation of liability provided above shall be interpreted in a manner that, to the extent possible, most closely approximates an absolute disclaimer and waiver of all liability.
Creative Commons Attribution-NonCommercial 4.0 International License. Section 5 – Disclaimer of Warranties and Limitation of Liability.
https://creativecommons.org/licenses/by-nc/4.0/legalcode